Training Your Model
Introduction
Training (sometimes called fitting) your model is when you build out the implementation of your modeling technique, connect data to it, and press start. Here we explore what this process entails.
Planning the Architecture
Here we plan the structure of our model. Often, this is where we determine the approximate shapes that $\hat{f}$ is likely to take on and plan our architecture in accordance- you will recall that shaping is heavily influenced by how we parameterize, if we choose to do so. For instance, in a regression model, this often takes the form of determining if a simple or curvilinear line is needed, detecting possible interaction effects, etc.
If you have hyperparameters (also called tuning parameters), this is the place to list them out and consider possible ranges for them. Neural networks are a great example here because they often have so many hyperparameters, including the number of hidden layers, number of neurons in each layer, the activation functions used, what type of gradient descent algorithm and its associated optimization, and much more. We need to come up with a way to decide on how to the different tuning paramaters; sometimes this can amount to testing out numerous different models and seeing what works.
This step is where the planning in thinking about the output comes into play. If we are trying to imagine what the approximate structure for our model should be, how can we do that if we don’t know what we want to see as output?
With relatively simple models, maybe going right ahead to code and see what works is a great idea. Other times, with more complex models and lots of data, writing out our model architecture is not a bad idea. Here’s a rough template to give you an idea:
-
What Do We Want To See As Output:
-
Model(s) To Build:
-
Parameters in the model(s):
-
Hyperparameters (and optimization of those hyperparameters, if applicable):
Code Implementation
Once you’ve got your model architecture sketched, now we implement this in code. Packages/libraries differ in implementation, but there are fairly robust packages that make architecture implementation fairly straightforward once you learn how they work. A great example of code implementation with a few hyperparameters for a neural network using Tensorflow can be seen in the neural network introduction notebook.
Training/Fitting
Sometimes you will see the training/fitting process called "learning", and this is where the notion of machine "learning" comes from: our machine is learning/training/fitting its model based on the training data.
Again the implementation details differ wildly depending on which package/library you are using. The model will use the validation set to verify and/or optimize itself along the way, depending on your architecture and model choice.
Most of the time its a single line of code which starts the training process. Again, you can see a simple example of this on the neural network introduction notebook.
By the end of this process, your model will have its parameters discovered/chosen, or if you are using a non-parametric method, it will have taken at least 1 complete iteration in its algorithm. Some non-parametric methods can return differing results training on the same data and running many iterations, such as clustering. You can see an example of this process below, where no new data is added, but the algorithm determines that the clusters are slightly different at each iteration until stopping.
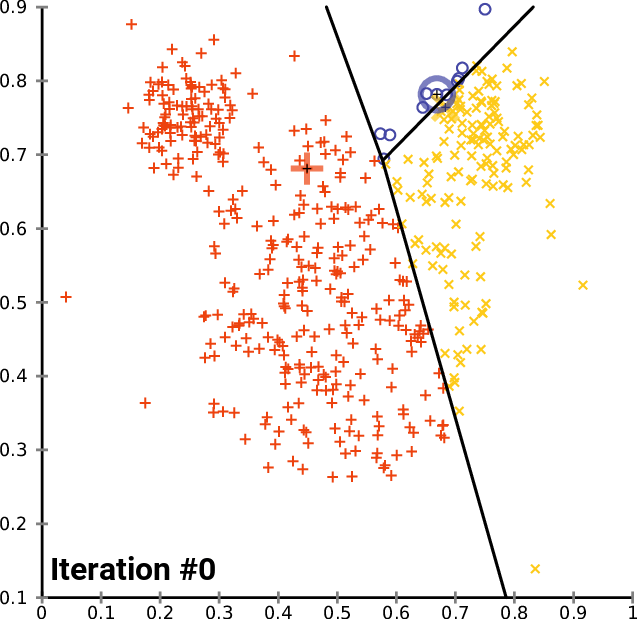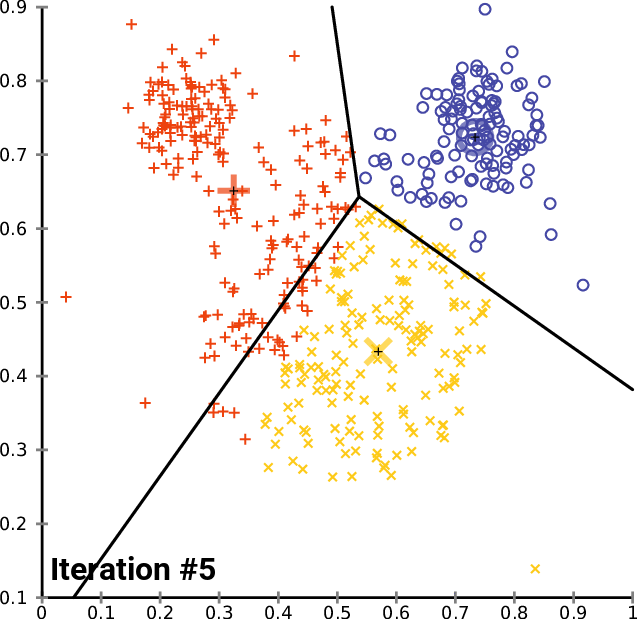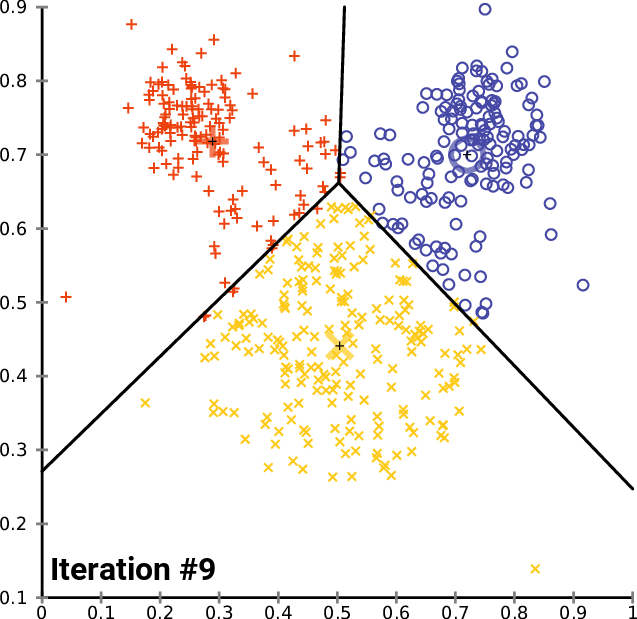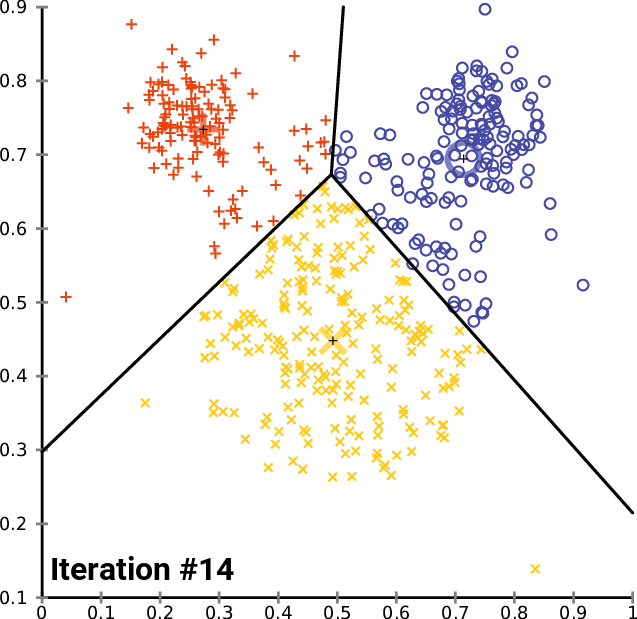
Testing
Once we are finished training, and we’ve assessed the model’s accuracy and we are satisfied with its training, we can test the model to see how well it performs on data that is unbiased. You may recall that although its optional, the highly recommended test split can be used to test a model after its been trained. The reason why we set aside this test split is so we have data that was completely unused for the model training process. You will recall that the training data was used to train the data; the validation data was used to validate (and/or optimize the tuning parameters) the training results during training. But the test split was not used at all for training, hence why it is considered "unbiased".
You can think of this step sort of like a new car leaving the factory. It ought to be test driven for at least a few miles before being sold to a customer, just to verify that the basic things are right. Often, testing is done on samples of data, and metrics are taken again; for instance, what percentage of images are correctly classified as cats in a test set of dog and cat images? Here we get to see the real results of our labor.