STAT 29000: Project 2 — Spring 2022
Motivation: Web scraping is is the process of taking content off of the internet. Typically this goes hand-in-hand with parsing or processing the data. Depending on the task at hand, web scraping can be incredibly simple. With that being said, it can quickly become difficult. Typically, students find web scraping fun and empowering.
Context: In the previous project we gently introduced XML and xpath expressions. In this project, we will learn about web scraping, scrape data from a news site, and parse through our newly scraped data using xpath expressions.
Scope: Python, web scraping, XML
Dataset(s)
You will be extracting your own data from online in this project — there is no provided dataset.
Questions
Question 1
The Washington Post is a very popular news site. Open a modern browser (preferably Firefox or Chrome), and navigate to www.washingtonpost.com.
|
Throughout this project, I will be referencing text and tools from Firefox. If you want the easiest experience, I’d recommend using Firefox for at least this project. |
By the end of this project you will be able to scrape some data from this website! The first step is to explore the structure of the website.
To begin exploring the website structure right click on the webpage and select "View Page Source". This will pull up a page full of HTML. This is the HTML used to render the page.
Alternatively, if you want to focus on a single element on the web page, for example, an article title, right click on the title and select "Inspect". This will pull up an inspector that allows you to see portions of the HTML.
Click around on the website and explore the HTML however you like.
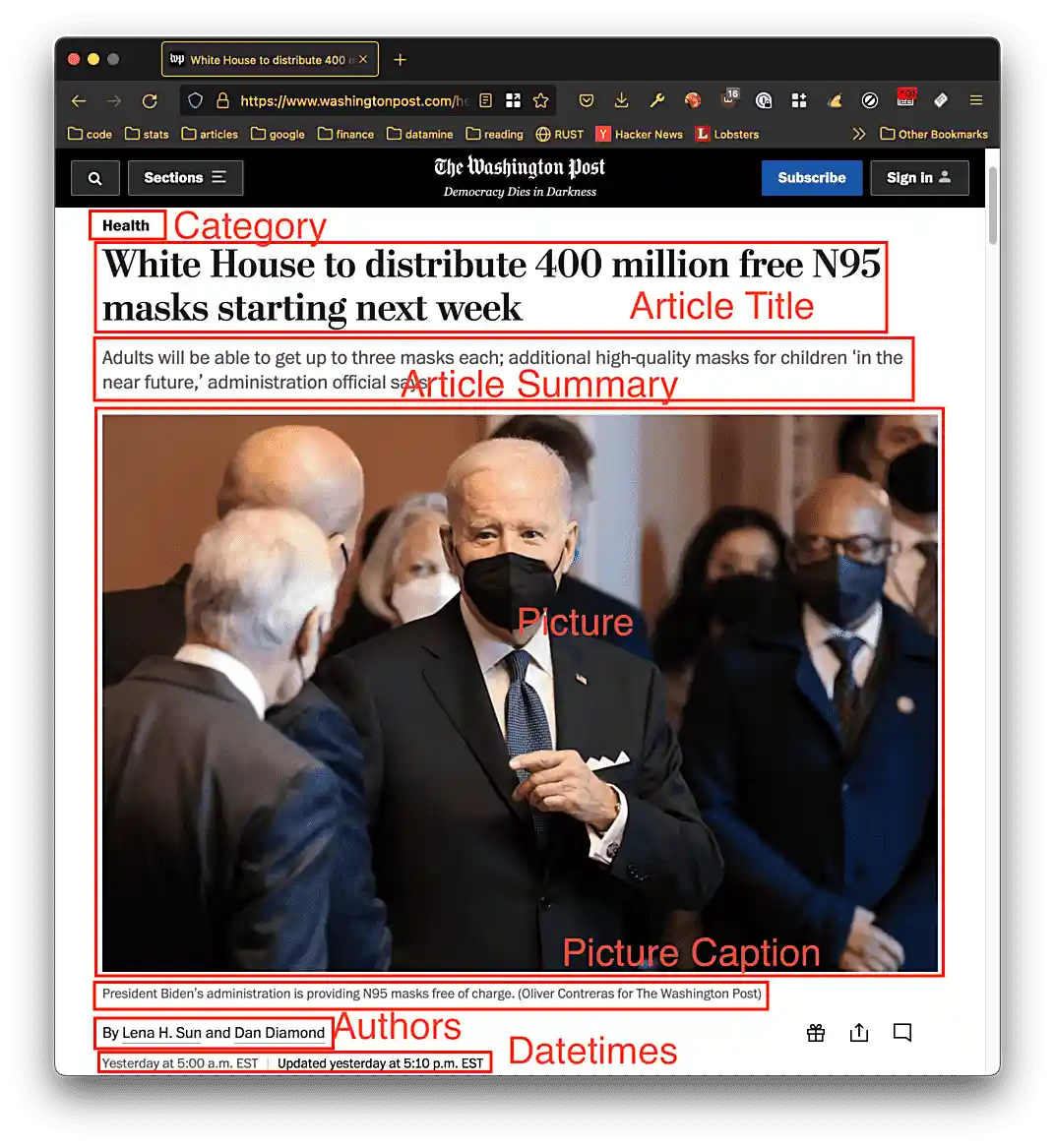
Open a few of the articles shown on the front page of the paper. Note how many of the articles start with some key information like: category, article title, picture, picture caption, authors, article datetime, etc.
For example:
Copy and paste the header element that is 1 level nested in the main element. Include just the tag with the attributes — don’t include the elements nested within the header element.
Do the same for the article element that is 1 level nested in the main element (after the header element).
Put the pasted elements in a markdown cell and surround the content with a markdown html code block.
-
Code used to solve this problem.
-
Output from running the code.
Question 2
In question (1) we copied two elements of an article. When scraping data from a website, it is important to continually consider the patterns in the structure. Specifically, it is important to consider whether or not the defining characteristics you use to parse the scraped data will continue to be in the same format for new data. What do I mean by defining characterstic? I mean some combination of tag, attribute, and content from which you can isolate the data of interest.
For example, given a link to a new Washington Post article, do you think you could isolate the article title by using the class attribute, class="b-l br-l mb-xxl-ns mt-xxs mt-md-l pr-lg-l col-8-lg mr-lg-l"? Maybe, or maybe not. It looks like those classes are used to structure the size, font, and other parts of the article. In a different article those may change, or maybe they wouldn’t be unique within the page (for example, if another element had the same set of classes in the same page).
Write an XPath expression to isolate the article title, and another XPath expression to isolate the article summary or sub headline.
|
You do not need to test your XPath expression yet, we will be doing that shortly. |
|
Remember the goal of the XPath expression is to write it in such a way that we can take any Washington Post article and extract the data we want. |
-
Code used to solve this problem.
-
Output from running the code.
Question 3
Use the requests package to scrape the web page containing our article from questions (1) and (2). Use the lxml.html package and the xpath method to test out the XPath expressions you created in question (2). Use the expressions to extract the element, then print the contents of the elements (what is between the tags). Did they work? Print the element contents to confirm.
-
Code used to solve this problem.
-
Output from running the code.
Question 4
Use your newfound knowledge of XPath expressions, lxml, and requests to write a function called get_article_links that scrapes the home page for The Washington Post, and returns 5 article links in a list.
There are a variety of ways to do this, however, make sure it is repeatable, and only gets article links.
|
The |
-
Code used to solve this problem.
-
Output from running the code.
Question 5
Write a function called get_article_info that accepts a link to an article as an argument, and prints the information in the following format:
Category: Health Title: White House to distribute 400 million free N95 masks starting next week Authors: Lena H. Sun, Dan Diamond Time: Yesterday at 5:00 a.m. EST
|
Of course, the Time section may change. Just use whatever text they use in the article. It could be an actual date or something like in the example where it said "Yesterday…". |
In a loop, test out the get_article_info function with the links that are returned by your get_article_links function.
|
For the authors part, you may find it very difficult to find a single, repeatable way to extract the authors. The reason is that the authors are listed twice within the article. Consider first finding both groups of authors and then use the first of the 2 resulting elements as a starting point to find the authors. You can use the ".//" to search the current element. |
|
For the time part, you may find it difficult to print both the "Yesterday at" and the actual time portion. Use a similar trick that you used for the authors. First find the node with "Yesterday at" text, then use that node as a starting point to find the next node that contains the time info. If you are stumped — make a post in Piazza! |
-
Code used to solve this problem.
-
Output from running the code.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connect ion, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. In addition, please review our submission guidelines before submitting your project. |